Textreme is an OCR app that simplifies the process of getting data trapped in images into a useful format. As the app grows, we are moving closer to a fully serverless architecture. Much of the processing is already event driven, with compute provided by AWS Lambda functions. The next big challenge was transactional storage, currently handled the traditional way, in a Relational Database Management System (RDBMS). This blog post goes over some of our experiences migrating the app to a NoSQL database, Amazon DynamoDB.
What exactly is DynamoDB?
DynamoDB is a NoSQL database, built for consistent, reliable performance. Being NoSQL, it has no concept of relationships between tables. Our first challenge was therefore to understand how to refactor an existing relational data structure to work without joins and foreign keys. This was an alien concept to the Textreme dev team, but there are a few options.
Data Modelling in DynamoDB
RDBMS systems are optimised for normalised data, that is, data where duplication has been eliminated. This gives efficient storage (you don’t have to store the same information more than once) but less efficient querying (you want to know what Product Code 1882332 is? Left join to the PRODUCT table). DynamoDB accepts the penalty of data duplication (storage is cheap) in exchange for very fast, scalable data access to items with a known key.
It’s possible to simply recreate your existing RDBMS table structure in DynamoDB. For the purposes of this blog post, let’s model two tables from the Textreme database: Files and Users. A File has an owning User, a User can have zero or more Files.
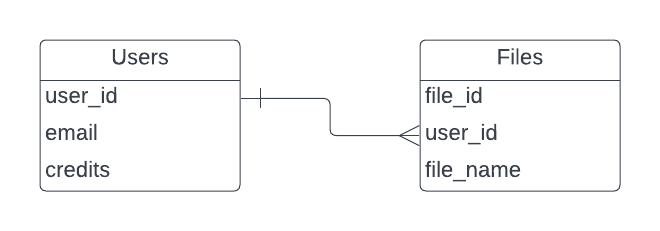
If we want to get a User’s data, and all of their Files, we would make one call to the Users Table, then another call to the Files table. That would work, but it misses the benefit of DynamoDB. We are relying on multiple network requests to the database, and we have to wrangle the data together in our application code. There is another way to model this, so we can retrieve everything we need in a single request.
Single Table Design
If we have no joins, but we still want our User and all their Files in a single request, the only logical conclusion is we have to squash everything together into a single table. Wait, what? Yes. A single table for everything. But how do we go about that in practice?

Data Access Patterns
The first step is to identify your applications data access patterns. You have to do this upfront; adding new access patterns after the fact can be hard, and will most likely require you to re-write the database. So, for Textreme, with Users and Files, we rely on the following access patterns:
- Access a User record by user ID
- Access a User record by email address
- Return all of a User’s Files by user ID
Let’s take the first access pattern. User ID is the primary key of the existing RDBMS User table. The primary key of a DynamoDB table can either be a single partition key, or a composite of the partition key and sort key. Like a RDBMS, a DynamoDB primary key must reference a single record. In order to query a DynamoDB table, you must know the record’s partition key. So we could design a DynamoDB table that looks like this:

But if we call our partition key User ID, how will we fit File records into this table as well?
Overloading the Keys
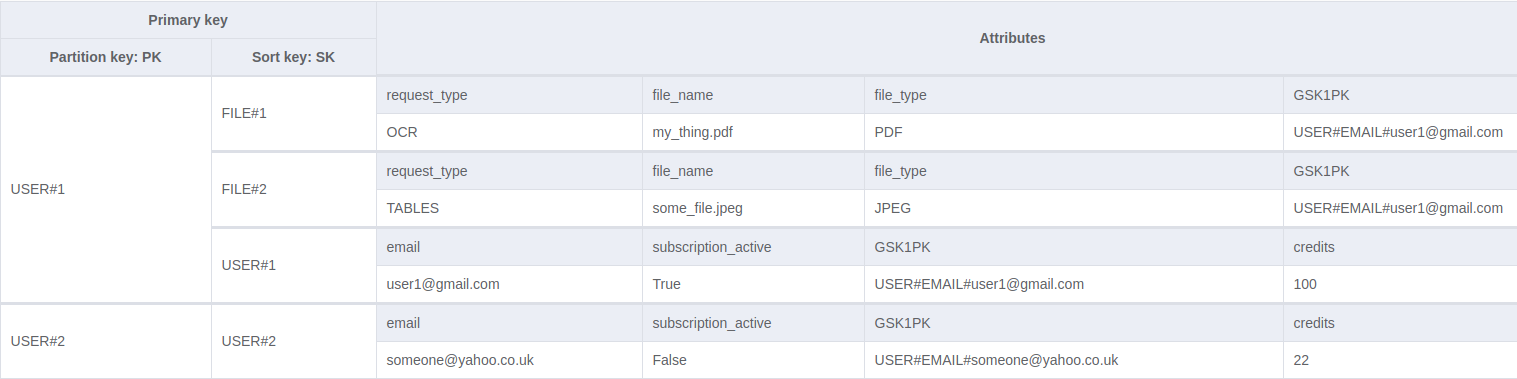
The secret is craming more data into our partition and sort keys. Rather than a key named “User ID”, we give them generic names, “PK” and “SK”.

Now we can reuse the sort key, and add the user’s file records as well. By adding textual type information to the keys, we can easily limit our query to a subset of records.

Accessing by Email
We can now access a User’s record by user ID, and get their files. How how do we retrieve a record using a different key altogether? This is where another DynamoDB concept comes in; the Global Secondary Index (GSI). A GSI allows us to define another primary key (partition key, or partition key and sort key composite) for a table. We define our GSI with a new partition key (GSI1PK), and reuse the existing sort key.
Writing Queries
That’s the theory dealt with. But how do we actually query the new table? Let’s take each access pattern in turn, and compare it to the RDBMS query.
Access a User record by user ID
An RDMS query would look something like this
select * from USERS where user_id = "998877"
Which becomes the following in our single table DynamoDB (we are using Python here, but the concept is the same no matter the API):
table = res.Table("MySingleTable")
user_item = table.query(
KeyConditionExpression=Key("PK").eq(f"USER#{str(user_id)}")
& Key("SK").eq(f"USER#{str(user_id)}")
)
Access a User record by email address
This is imple in the RDBMS, email address is just another field on the table.
select * from USERS where email = "someone@email.com"
And with our GSI, it’s simple in DynamoDB too:
table = res.Table("MySingleTable")
user_item = table.query(
IndexName="GSI1",
KeyConditionExpression=Key("GSI1PK").eq(f"USER#EMAIL#{str(user_email)}"),
)
Return all of a User’s Files by user ID
Time for our first RDBMS join.
select U.*, F.* from USERS as U LEFT JOIN FILES as F on (U.user_id = F.user_id)
And from our single DynamoDB table, we can either return the user and all their files in one go, or, using the “begins with” filter, restrict the results to just the file records:
table = res.Table("MySingleTable")
file_items = table.query(
KeyConditionExpression=Key("PK").eq(str(f"USER#{user_id}"))
& Key("SK").begins_with("FILE#"),
)
Conclusion
With the design complete the next stage of the process is changing the application code to query the new structure. The next part of this blog post series covers moving from SQLAlchemy to a combination of the AWS Boto3 client and (Pydantic)[https://pydantic.dev/] data models. Stay tuned!
Futher reading on DynamoDB:
The What, Why, and When of Single-Table Design with DynamoDB - Alex DeBrie
AWS Documentation
Fundamentals of Amazon DynamoDB Single Table Design with Rick Houlihan